
Steve Bottos
Lead Machine Learning Engineer | Victoria, BC
AI helped with writing this one. It came up with the stupid “From Crash and Burn…” title. I’m gonna allow it because it’s kind of endearing.
From Crash and Burn to a Smooth Landing: A Reinforcement Learning Journey
In the world of reinforcement learning, we often rely on carefully crafted state vectors to feed our agents. But what if we could bypass this feature engineering step and let the agent learn directly from raw pixels? This post chronicles my journey attempting just that: treating the classic LunarLander-v3 control problem as a video understanding task. It was a journey of initial failures, deep dives into the mechanics of Proximal Policy Optimization (PPO), and ultimately, a successful landing.
A Quick Code Dive
For those interested in the code, here’s a brief overview of the project structure:
train.py: The main training script. It uses PPO written from scratch, Gymnasium for the environment, and MLflow for logging. It’s set up to useAsyncVectorEnv, which means we can compute rollout buffers much quicker than if we serial environments.models.py: This file contains all the different model architectures I experimented with.configs/: This directory holds all the YAML configuration files for my experiments. If you’re reproducing, this contains your starting point.
… And that’s it, it’s sparse in files, but dense in logic.
The First Attempt - Transformer Based Architecture
My initial idea was simple: instead of feeding the agent a state vector, I would feed it a sequence of rendered frames from the game. This turns the problem into a video analysis task, where the agent has to learn to land the spacecraft by watching it.
I started with a TemporalResNet architecture – a pre-trained ResNet to extract features from each frame, followed by a Transformer to model the temporal relationships. The idea was sound, and the agent was learning, just incredibly slowly. My initial impulse was to reach for a transformer because that’s the most familiar architecture to me these days, but I simply did not have the patience to wait months for results.
Evolving the Architecture
Transformers have no inductive bias - they make no assumptions on the input data. These assumptions must be learned. It was possible that the Lunar Lander environment combined with the weak learning signal provided by the vision-only constraint I imposed upon myself was just not enough to teach the transformer what to assume. I needed something simpler.
- TemporalResNet -> TemporalResNetGRU: I replaced the Transformer with a Gated Recurrent Unit (GRU). The idea was that a recurrent model might be better suited for capturing the stateful nature of the environment much quicker. This proved to work, and as a result I saw a much faster ascent from consistent deep negative rewards to some positive rewards after an overnight training session.
Hyper Parameter Puzzles
It took a while to get the hyper-parameters correct. My two main diagnostic curves were PPO clipping and KL divergence, which both provide a measure of how much a current policy is trying to diverge from the pre-computed rollout buffer (the previous policy). I tried to keep clipping between 0.1-0.2 and KL divergence below 0.3 for early training.
For later stages of training (>180 average rewards), I relaxed the entropy coefficient to discourage exploration from a working policy, and dialed back the learning rate. Eventually I was hitting >200 rewards consistently, which is “solved” for Lunar Lander.
A Smooth Landing (Results)
After all the debugging and architectural changes, I was finally able to train an agent that could consistently land the spacecraft. Here are a few examples of successful landings:
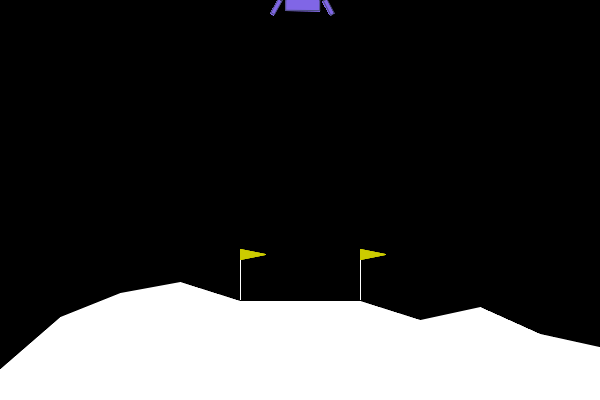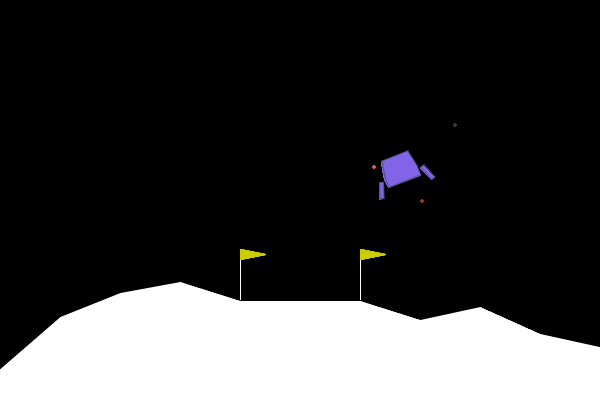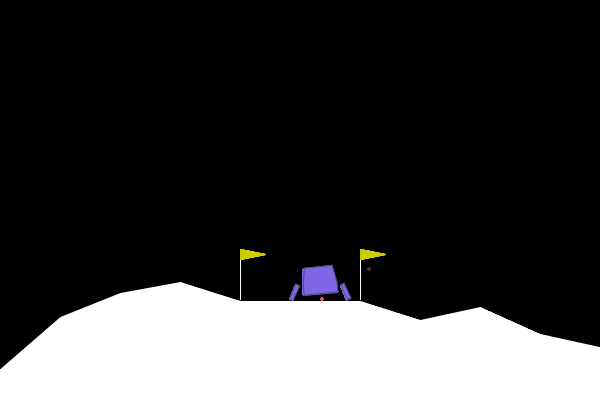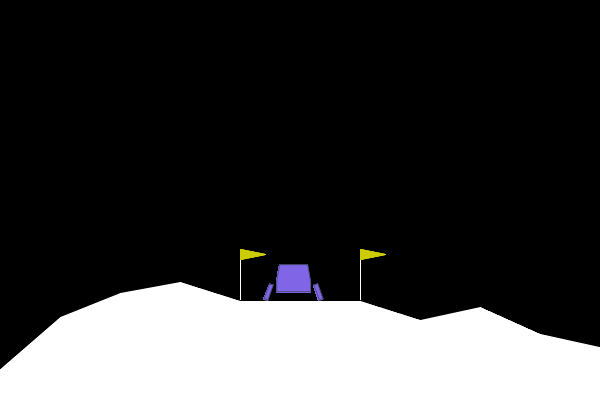


Conclusion
This project was a fantastic learning experience. It was a powerful reminder that in reinforcement learning, the journey is just as important as the destination. The initial failures were frustrating, but they forced me to dig deeper into the fundamentals of PPO and to think more critically about the interplay between model architecture, hyperparameters, and training stability. In the end, I not only managed to train a successful pixel-based agent, but I also gained a much deeper understanding of the entire process.